
记一次阿里云Kubernetes集群内部服务域名解析不稳定的排查
最近,由于项目需求新建了一个阿里云托管版Kubernetes集群(Managed ACK),但是发现部署在集群中的微服务相互调用不稳定,导致业务不可用。经过排查,最终发现添加在集群工作节点上的安全组与当前集群的安全组不一致,使得跨节点的Pod访问流量被阻止掉了。本文将详细介绍这一问题的排查过程。
问题描述
通过以下命令在Pod中通过域名访问某个服务时,有时能正常访问,有时访问不了。
1 | for i in {1..100};do curl http://<service name>.<namespace>.svc.cluster.local;done |
错误大致为:
1 | Couldn't resolve host xxxx |
从错误信息来看,是域名解析出了问题。用nslookup命令去检查域名解析,发现解析确实不稳定。
1 | for i in {1..100};nslookup <service name>.<namespace>.svc.cluster.local;done |
问题排查
ACK集群的结构介绍
在详细排查问题之前,先了解下阿里云ACK集群的结构。阿里云容器服务Kubernetes版(Alibaba Cloud Container Service for Kubernetes,简称容器服务ACK)包含了专有版Kubernetes(Dedicated Kubernetes)、托管版Kubernetes(Managed Kubernetes)、Serverless Kubernetes三种形态。本文讨论的是托管版ACK,结构如下:
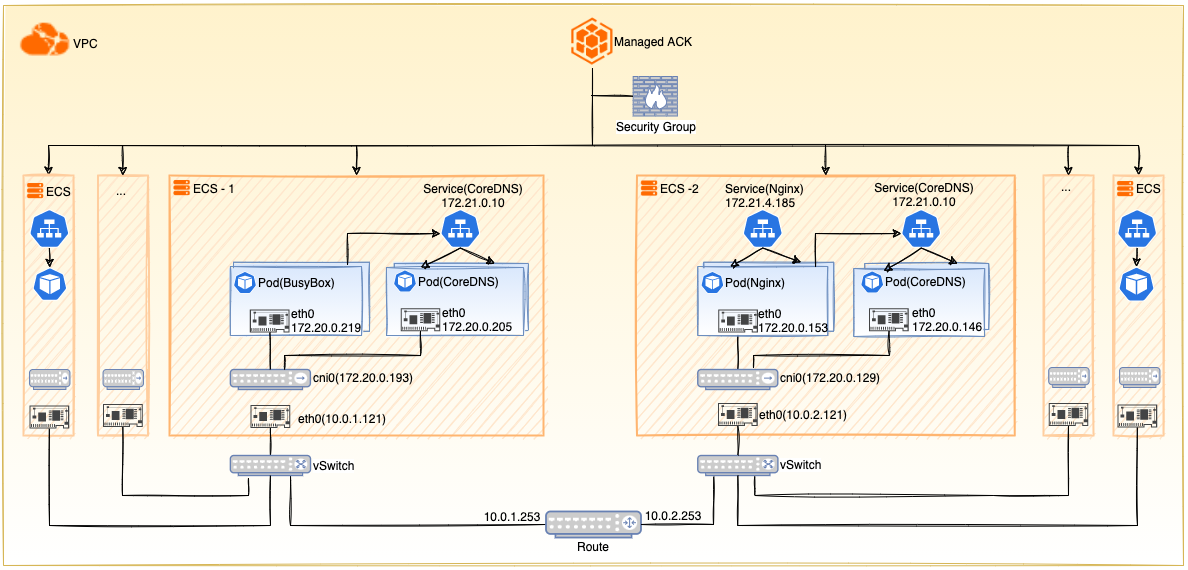
集群的详细信息: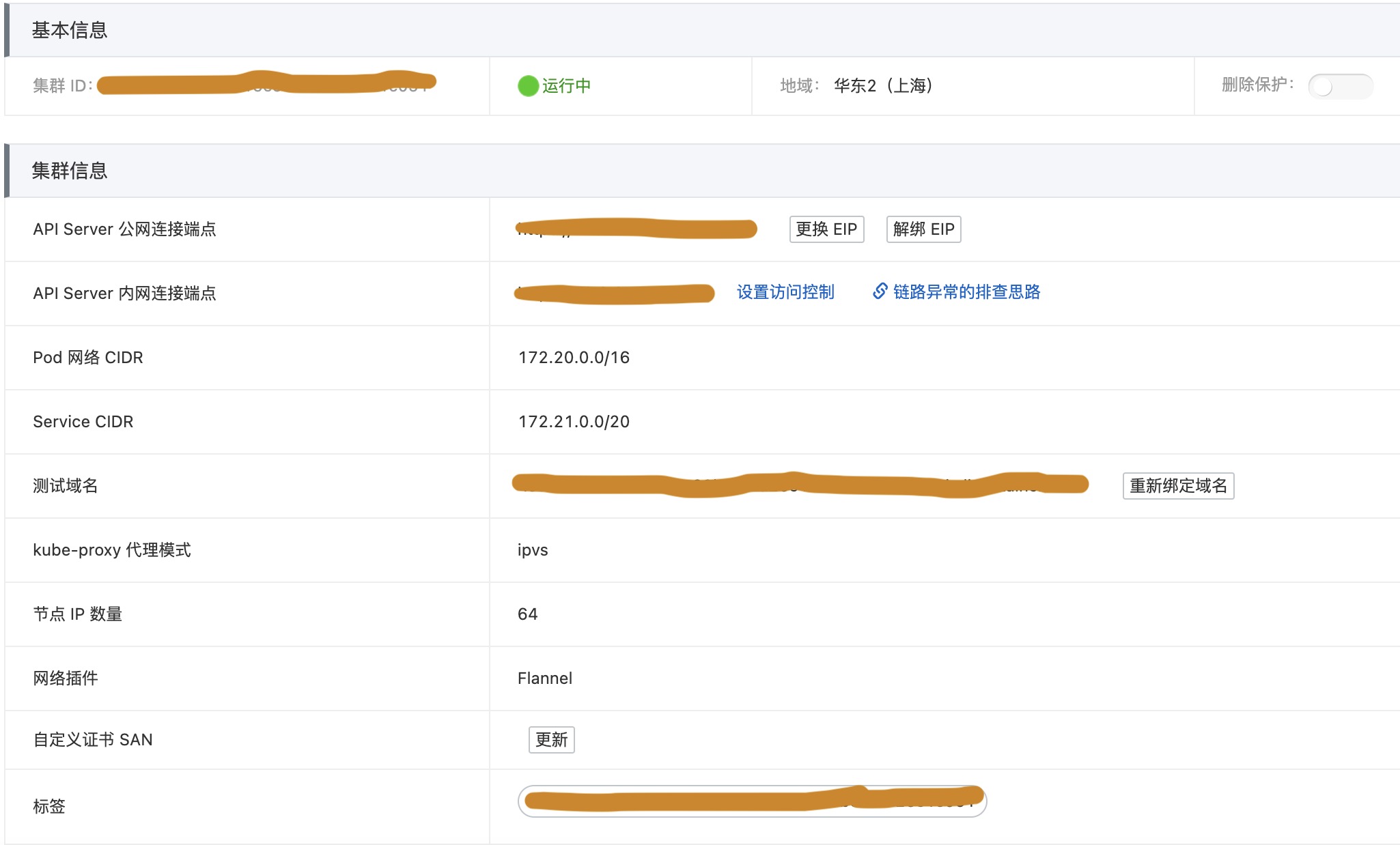
- Pod网络类型是Flannel,CIDR: 172.20.0.0/16。每个工作节点的最大的Pod数量为64 (ECS-1 CIDR: 172.20.0.192/26, ECS-2 CIDR: 172.20.0.128/26 …)
- Service CIDR: 172.21.0.0/20
- 系统组件CoreDNS目前有两个Pod,分别运行在两个工作节点上
检查前的准备
分别在CoreDNS Pods所在的两个工作节点上各启动一个测试Pod:Pod(Busybox),Service(Nginx) + Pod(Nginx)。
将测试Pods分散在不同的工作节点上,并调度到CoreDNS Pods所在的工作节点中,这样既能测试同一节点上的CoreDNS访问,也能测试跨节点的CoreDNS访问。
- 在ECS-1主机上启动Pod(Busybox)
1 | apiVersion: apps/v1 |
通过nodeSelector绑定到ECS-2主机(10.0.2.121)上。
检查系统组件CoreDNS
参考官方文档 Debugging DNS Resolution
检查CoreDNS Pod是否正在运行
执行命令kubectl get pods验证CoreDNS Pod正在运行。
1 | kubectl get pods -l k8s-app=kube-dns -n kube-system |
1 | NAME READY STATUS RESTARTS AGE |
如果没有看到CoreDNS Pod正在运行,可能在你当前的环境里缺省没有安装CoreDNS插件,你可能需要手动安装它。如果看到CoreDNS Pod失败,执行命令kubectl describe pod检查CoreDNS Pod的事件。
1 | kubectl describe pod -l k8s-app=kube-dns -n kube-system |
检查CoreDNS Pod是否有运行时错误
运行状态正常的Pod并不代表没有错误,有时程序会处理异常以保证服务的可用性。所以需要执行命令kubectl logs检查Pod的日志是否有任何可疑或异常的消息。
1 | kubectl logs -l k8s-app=kube-dns -n=kube-system |
正常的CoreDNS日志实例:
1 | .:53 |
检查CoreDNS服务
执行命令kubect get svc -l k8s-app=kube-dns -n=kube-system检查CoreDNS服务是否存在。如果服务不存在,参考调试服务进行排查。
1 | NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE |
检查CoreDNS endpoints对象是否存在
执行命令kubectl get endpoints检查CoreDNS endpoints是否存在。
1 | NAME ENDPOINTS AGE |
如果没有检查到endpoints,参考调试服务文档中的endpoints段落。
检查DNS查询是否被CoreDNS处理
首先,修改CoreDNS的配置添加日志插件。
执行以下命令打开CoreDNS的配置:
1 | kubectl edit cm coredns -n kube-system |
在Corefile段落添加log:
1 | apiVersion: v1 |
其次,执行以下命令打开CoreDNS Pods日志:
1 | kubectl logs --tail 20 -f -l k8s-app=kube-dns -n kube-system | grep -E "\"A IN nginx.default.svc.cluster.local" |
通过grep命令仅提取域名nginx.default.svc.cluster.local的DNS查询日志,后面我们将查询这个域名。
接下来,执行以下命令进入Pod(Busybox):
1 | kubectl exec -it pod/busybox-757d9599bd-hdhhq -- sh |
在Pod(Busybox)中,重复查询域名nginx.default.svc.cluster.local多次,例如100次:
1 | for i in $(seq 1 100); do nslookup nginx.default.svc.cluster.local; done |
检查CoreDNS Pods日志,看是否有同样次数的域名解析日志:
1 | [INFO] 172.20.0.219:48418 - 4 "A IN nginx.default.svc.cluster.local. udp 49 false 512" NOERROR qr,aa,rd 96 0.000179197s |
如果域名解析的次数少于查询的次数,说明有些解析请求没有被CoreDNS获取,客户端nslookup命令就会出现有时解析成功,有时解析失败的情况。这也证明了前面描述的域名解析不稳定的问题。
直接调用CoreDNS的Pod IP解析域名
直接使用CoreDNS Pod IP可以避免CoreDNS服务到CoreDNS Pod的代理解析。如果检查下来问题仍旧存在,说明从CoreDNS服务到CoreDNS Pod的代理解析没有问题,否则需要详细检查kube-proxy的状态。
Pod(Busybox)缺省使用CoreDNS服务IP调用CoreDNS解析域名。执行以下命令可以查看Pod(Busybox)中的DNS配置:
1 | kubectl exec -it pod/busybox-757d9599bd-hdhhq -- cat /etc/resolv.conf |
1 | nameserver 172.21.0.10 |
172.21.0.10是CoreDNS的服务IP。
编辑Pod(Busybox)中的/etc/resolv.conf将nameserver换成同一节点上的CoreDNS Pod IP(172.20.0.205),执行以下命令检查Nginx服务域名的解析情况:
1 | for i in $(seq 1 100); do nslookup nginx.default.svc.cluster.local; done |
测试下来发现使用同一个节点上的CoreDNS Pod解析域名正常且稳定。
将Pod(Busybox)的nameserver换成另一个节点上的CoreDNS Pod IP(172.20.0.146),再执行上面同样的测试发现域名解析都失败了。 这个测试说明Pod(Busybox)可以访问同一节点上的CoreDNS Pod,但是不能访问另一个节点上的CoreDNS Pod,也就是跨节点的Pod之间无法访问。接下来就需要检查跨节点Pod之间的路由信息是否正确了。
检查从Pod(Busybox)到不同节点上的CoreDNS Pod(172.20.0.146)的路由信息
Pod(Busybox)里的路由信息

从Pod(Busybox)出来的流量会通过红色的路由规则进入到节点ECS-1。VPC里跨节点之间的路由信息
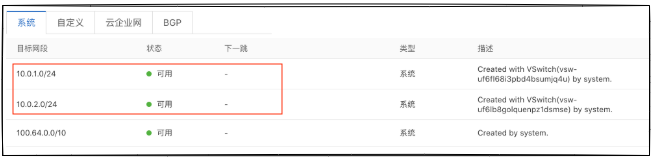
红框中的系统路由规则使两个节点之间路由可达。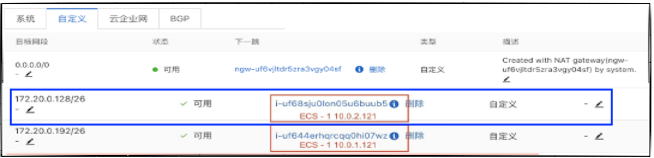
蓝框中的路由规则使流量从ECS-1路由到ECS-2中。ECS-2的路由信息
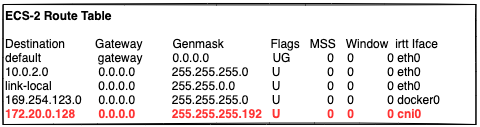
红色路由规则使得流量从ECS-2路由到网桥接口cni0,最终由cni0根据目的Pod IP地址进入CoreDNS Pod(172.20.0.146)。
从路由分析下来看,跨节点Pod之前相互访问没有问题。接下来就需要检查施加在工作节点上的安全组规则,看流量是否被禁止了。
检查安全组
通过这个检查,最终发现工作节点上的安全组并不是当前集群对应的安全组,从而导致所有跨节点之前的Pod访问流量被禁止了。安全组用错的原因是在新建ACK集群时并没有创建新的节点而是选择了已经存在的节点。
问题解决
找到问题后,解决方案就简单了,也就是将所有的工作节点的安全组全部换成当前集群的安全组。
结束语
对于这次的问题定位和解决花费了一定的精力,而且这个问题未来也可能再次出现。所以,我们可以将跨节点Pod之间的网络连通性纳入到监控系统中,这样可以保证下次同样的问题出现时,能够通过监控系统快速的发现和定位问题。
记一次阿里云Kubernetes集群内部服务域名解析不稳定的排查
https://blog.xsigeo.com/2021/09/06/aliyun-coredns-issue-tracking/
